 HII-CHI-mistry optical
HII-CHI-mistry opticalDESCRIPTION
HII-CHI-mistry is a python program that calculates, for gaseous nebulae ionized by massive stars or active galactic nuclei, the oxygen abundance in terms of 12+log(O/H), the nitrogen-to-oxygen ratio as log(N/O) and the ionisation parameter as log U, consistently with the direct method. This is done from the bayesian-like comparison between large grids of photoionization models and observed optical emission-line intensities. The methodology and the results are described in Pérez-Montero (2014, MNRAS, 441, 2663). The description and discussion of the code for its applicability in AGNs can be found in Pérez-montero et al (2019) and for Extreme Emission-Line Galaxies in Pérez-Montero et al (2021).
MOST RECENT VERSION
The most recent version for HII-CHI-mistry in the optical is version 5.3. The link leads to a compressed tar.gz file containing the python file of the code, the libraries of the models and a file with instructions. Previous versions of the program can be obtained in the History and Downloads section and they can also be found in GitHub.
How to run it
HII-CHI-mistry has been originally written in python v. 2.7, but from version 5 is only compatible with python 3. It requires the library numpy (versions previous to v2.0 use the library asciidata).
The program also requires the files of the emission line intensities predicted by the models, calculated assuming different sets of input conditions. All were calculated with Cloudy v.17. These libraries are stored in the folder Library_opt and include models for star-forming galaxies using spectral energy distributions from POPSTAR and from BPASS v.2.1.
For the NLR in AGNs, the libraries include results from models calculated using a double composite power-law with parameter alpha(UV) = -1.0 and for two possible values of alpha(OX) = -0.8 and -1.2. From version 5.2 the codee also admits grids of models defined by the user.
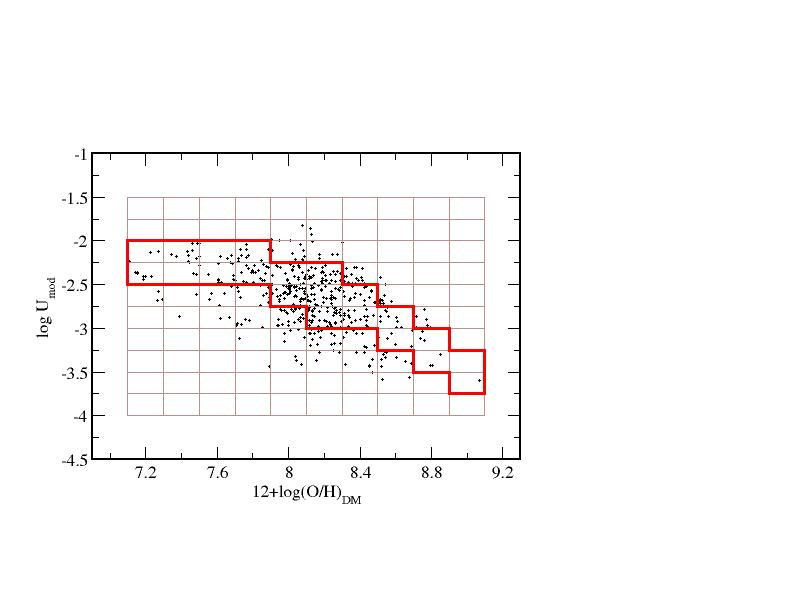
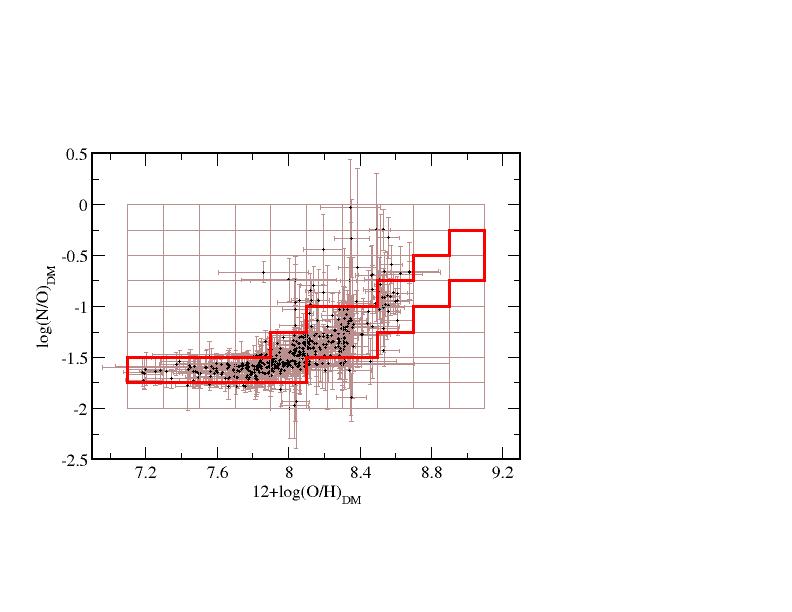
The code also requires files to constrain the model grids when a limited set of emission-lines are given as input. These are stored in the folder Constrains and can also be edited by the user. These files represent the set of models, limiting the values of log U at each Z (left picture), and limiting also the values of N/O, respectively (right picture).
To run the program, just type (for v5.2, in other versions use the name of the corresponding python script:
python HCm_v5.2.py
Once the input file has been specified in the prompt or by direct question, the code will ask about what SED of models is going to be used:
(1) Young POPSTAR massive cluster
(2) BPASS cluster models atmospheres with binaries
(3) double composite power-law AGN.
If AGN is selected, the code will also ask for the value of alpha(OX). considered in the models. Later, once selected the model SED, the program will ask for the template files used to constrain the models and for the possible use of a interpolated high-resolution grid (0: non-interpolated or 1:
interpolated). This will increase the resolution of the grid in O/H, N/O and log U in a factor 10, but it
will slow down the calculation.
The input file
It is a separated file written in text format with the information organised as a table whose first row contains the labels for the different columns, corresponding to the identification of each row and the emission line fluxes and their errors. The table can contain columns for other quantities, but the code will only read the following
labels:
ID for the identification name of the row
OII_3727 and eOII_3727 for [OII] 3727/Hß
and its error
NeIII_3868 and eNeIII_3868 for [NeIII] 3869/Hß and its error
OIII_4363 and eOIII_4363 for [OIII] 4363/Hß and its error
OIII_4959 and eOIII_4959 for [OIII] 4959/Hß and its error
OIII_5007 and eOIII_5007 for [OIII] 5007/Hß and its error. It is possible to give only one of
the two strong [OIII] nebular lines.
NII_5755 and eNII_5755 for [NII] 5755/Hß and its error
SIII_6312 and eSIII_6312 for [SIII] 6312/Hß and its error
NII_6584 and eNII_6584 for [NII] 6584/Hß and its error
SII_6725 and eSII_6725 for [SII]
6717+6731/Hß and its error. Alternatively, it is possible to give the two [sii]
lines individually, but the two are required.
OII_7325 and eOII_7325 for [OII] 7319+7330/Hß and its error
SIII_9069 and eSIII_9069 for [SIII] 9069/Hß and its error
SIII_9532 and eSIII_9532 for [SIII] 9532/Hß and its error
all the emission line fluxes must be given reddening corrected. If no information can be given about a certain line or its error it can
be typed as zero.
Results
If the input file is correct, the program will ask for the chosen SED and the use of
interpolations and it will begin to calculate the wanted
quantities and their corresponding errors.
The information will be displayed on the screen for each object, along with the ratio of completeness of the task. It will be also added an
index indicating if a specific constrain has been used, where
1: the complete grid is used only if a nebular-to-auroral emission-line ratio is given, e.g. [OIII] 5007/4363
> 0)
2: the log U limited grid is used (when [no nebular-to-auroral emission-line ratio is given (e.g. [OIII] 5007,4959/4363, [SIII] 9069,9532/6312, [NII] 6584/5755, or [OII] 3727/7325
)
3: the log U and N/O limited grid is used (if, besides, [NII]/[OII], [NII]/[OIII] or [NII]/[SII] cannot be obtained).
At the end, the program will create a file called using
the name of the input file + "_hcm-output.dat with the information of the used models, the identification of each row, the input emission line fluxes and their errors, and seven columns with the solutions corresponding to the following information:
grid index
12+log(O/H)
error of 12+log(O/H)
log(N/O) (-10 if grid 3 is used)
error of log(N/O)
log U
error of log(U) (take with care if constrains 2 or 3 are used)
History and Downloads
Here we list the different versions of the program with links to download them.
- Version 5.3 (2023/07). The code now admits auroral lines of [NII], [OII] and [[SIII], and the nebular optical [SIII] lines to better provide solutions with sets of emission-lines only in the red part of the spectrum. Now the emission-line ratio O3N2 is used for the calculation of N/O.
- Version 5.22 (2022/04). The code automatically sorts the grid of models to perform the interpolation. A bug related with the output writing when the [sII] lines are given separately has been fixed. A bug related with the output file when additional columns are presented in the input file has been fixed..
- Version 5.2 (2022/01). The user can now select the constraints to generate limited grids for the code. Libraries with models and constraints are stored in particular folders. Changes in the code to optimize the reading of the files. The output file no longer shows columns with emission lines that were not introduced as inputs..
- Version 5.1 (2021/03). New models from BPASS v. 2.1 have been incorporated. A detailed discussion of its application for Extreme Emission Line Galaxies is made in Pérez-Montero et al (2021).
- Version 5.0 (2020/11). From this version, it is not anymore required to give all lines in the input, but a label indicates what lines are given, including an identification one for each row.
- Version 4.2 (2020/05). From this version interpolated grid of models are calculated by the code, reducing the number of required library files.
- Version 4.1 (2019/08). Now compatible with python 3 and better management of the errors has been included
- Version 4.0 (2019/03). This version allows to calculate abundances for the NLR in AGNs using a double composite power law spectral energy distribution. The results and methods are discussed for this part in Pérez-montero et al (2019). Additionally the code now also uses [NeIII] 3868 å emission line to derive oxygen abundances. Finally the output file now includes a header with useful information.
- Version 3.1 (2018/12). Models have been now calculated using Cloudy v.17.00.
- Version 3.0 (2017/09). The errors of the input intensity lines are now considered in the calculation of the errors of the derived abundances and log U. To do so an iterative Monte-Carlo simulation is performed in the script. In addition, in the interpolated grid of models, this grid is only used once a first estimation of the results is obtained to reduce the time of calculation.
- Version 2.2 (2017/02) (In order to avoid some divergences in the calculation of O/H, it enhances in the interpolated mode the parameter defined to fix the number of constrained models once calculated N/O).<
- Version 2.0 (2016/01) (This version uses the library numpy, so asciidata is not anymore required. the results are now stored in an independent ascii file. Finally this version lets the user to choose a model grid of better resolution in O/H and N/O to smooth results around the knots of the model grid. In addition, the program uses all the models for the weighted means of the results, not just a subset of them as in previous versions.)
- Version 1.2 (2015/08) (It fixes a bug for observational sets with [OIII[ 4363 but without [NII] 6584 for N/O and it expands the metallicity range from 12+log(O/H) = 6.9).
- Version 1.0 (2014/04)